Welcome back on the blog! It’s been a long time since the last post I wrote. Today I want to talk about another advanced and hidden feature of Bifrost: Custom data structures. These can be used in your graphs or inside your compounds, and they can be quite useful with complex scenarios where dealing with only the standard data structures would start to make things too messy inside a visual programming framework.
Part 1: Primitive data types
Before we jump into the heart of subject, let’s start with the basics. Like with common programming languages, the data types in Bifrost are based on primitives data types. These are the lowest level data type which one can use. Each data types has a different size, which defines how much memory is used to store a value. Larger data types allow a wilder range of values to be used.
| Data types | Size | Range |
|---|---|---|
| bool (Boolean) | 8 bits | True or False |
| char (Integer) | 8 bits | -128 to 127 |
| uchar (Integer) | 8 bits | 0 to 255 |
| short (Integer) | 16 bits | -32,768 to 32,767 |
| ushort (Integer) | 16 bits | 0 to 66,536 |
| int (Integer) | 32 bits | -2,147,483,648 to 2,147,483,647 |
| uint (Integer) | 32 bits | 0 to 4,294,967,296 |
| long (Integer) | 64 bits | -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| ulong (Integer) | 32 bits | 0 to 18,446,744,073,709,551,615 |
| float (Floating-point) | 32 bits | 1.4e-44 to 3.4e+38 |
| double (Floating-point) | 64 bits | 4.9e-324 to 1.8e+308 |
| string | ~ | unicode characters |
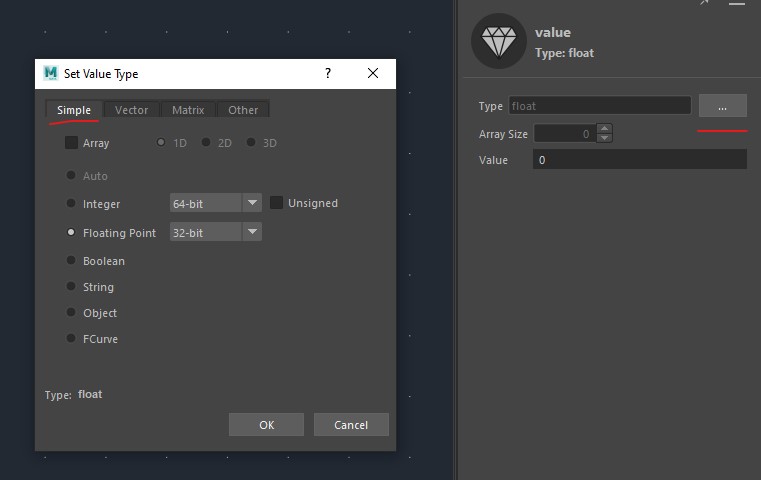
In Bifrost, these types are all listed in Simple tab of the Set Value Type dialog which is accessible by using a value node, and clicking the dots on the Parameters Editor, It is also available when right clicking on an auto-port of referenced nodes, and also any port of editable compounds.
Part 2: Data structures
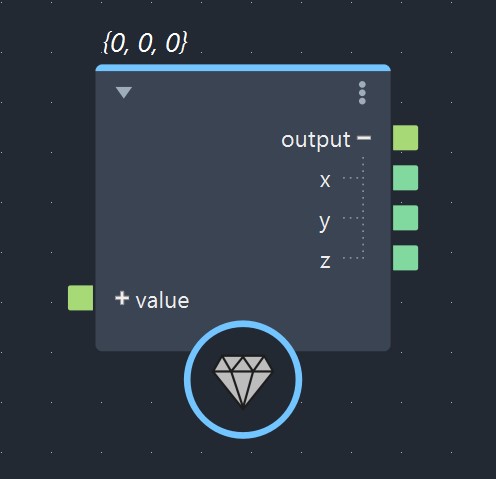
Now that we’ve learned about primitive data types, we can jump into the next subject and start talking about “Data Structures“. These are data types that are composed of multiple primitive data types. The most commonly used data structure is float3 (usually used as a vector or a color). It is simply composed of 3 float primitives. If you take a value node and set the type to Math::float3, and clickon the + icon, you can clearly see the 3 structure members are floats.
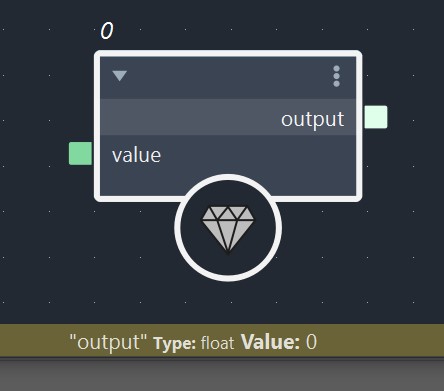
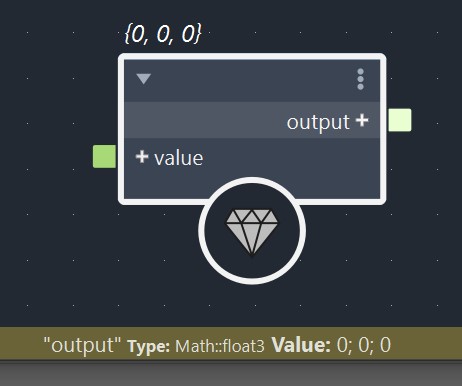
In Bifrost, Almost all data types that are not primitives are data structures. The easiest way to figure out if a data type is a data structure is to hover your mouse over a port and check the data type’s name in the info bar of the Graph Editor. If the name of the data type has a namespace, then you are dealing with a data structure. Only primitive types are using plain names. When using value nodes with single values, you can also check if there is a + icon, which indicates that the data types has members. Note that there are also data structures that will not show members. This is the case for hard-coded data types that have been compiled.
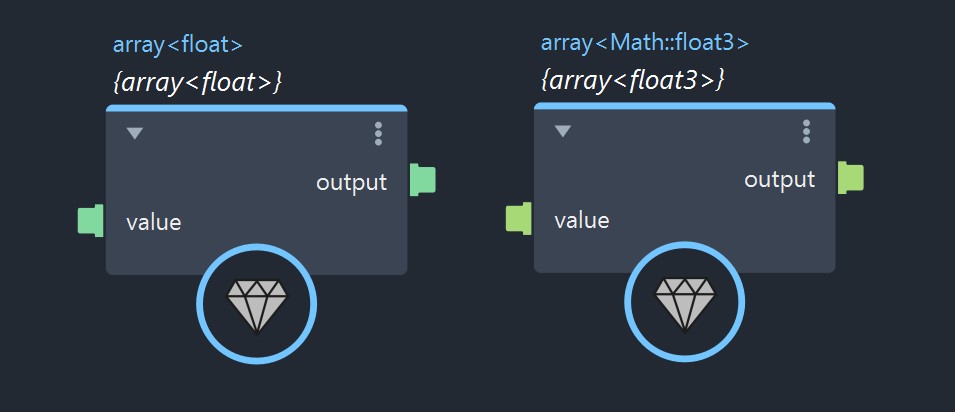
All data types in Bifrost can be used with arrays of multiple dimensions. When a data type is used in an array, Bifrost will change the data type’s name by enclosing the data type’s base namespace between the angle brackets of the array flag like this: array<xxx> . If we are dealing with multi-dimensional arrays, then the lower dimension’s data type full name will again gets enclosed inside an other array<>, and so on.
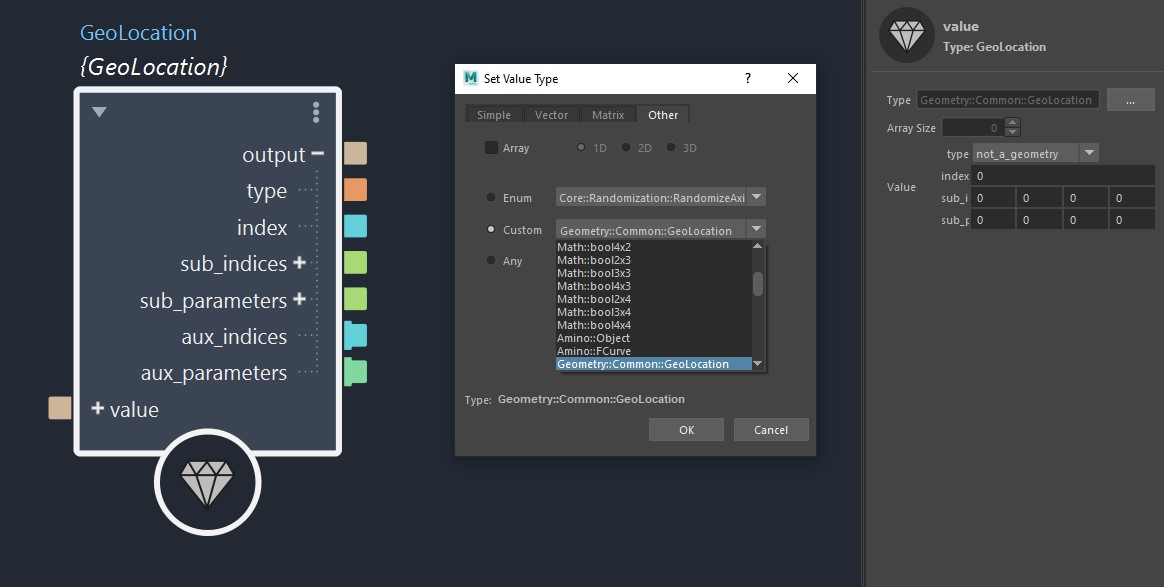
Most of the standard data structures in Bifrost are under the Math:: namespace, but there are also other data structures which can be found in the Other tab of the Set Value Type dialog. A good example of a built-in, advanced data structure is the GeoLocation. As you can see, a single geoLocation value stores other data structures like Math::float4 and Math::uint4, it is also storing array data types like array<float> and array<uint>, and it even holds an enum!
Here is a trick you can to decompose the data structure of an array. You can take a value node and set its type with the non-array version of the data type you wish to use. If you plug an array of the same data type as its input, the auto-looping feature of Bifrost kicks in and you can access all of the array’s data structure’s members. On the opposite, if you directly set the array variant of the data type on a value node, then the + icon disappear, and you lose the access to its members, which makes it useless to use a value node at all. This is why I recommend to always use non-array versions of data types with the value node and make it to auto-loop.

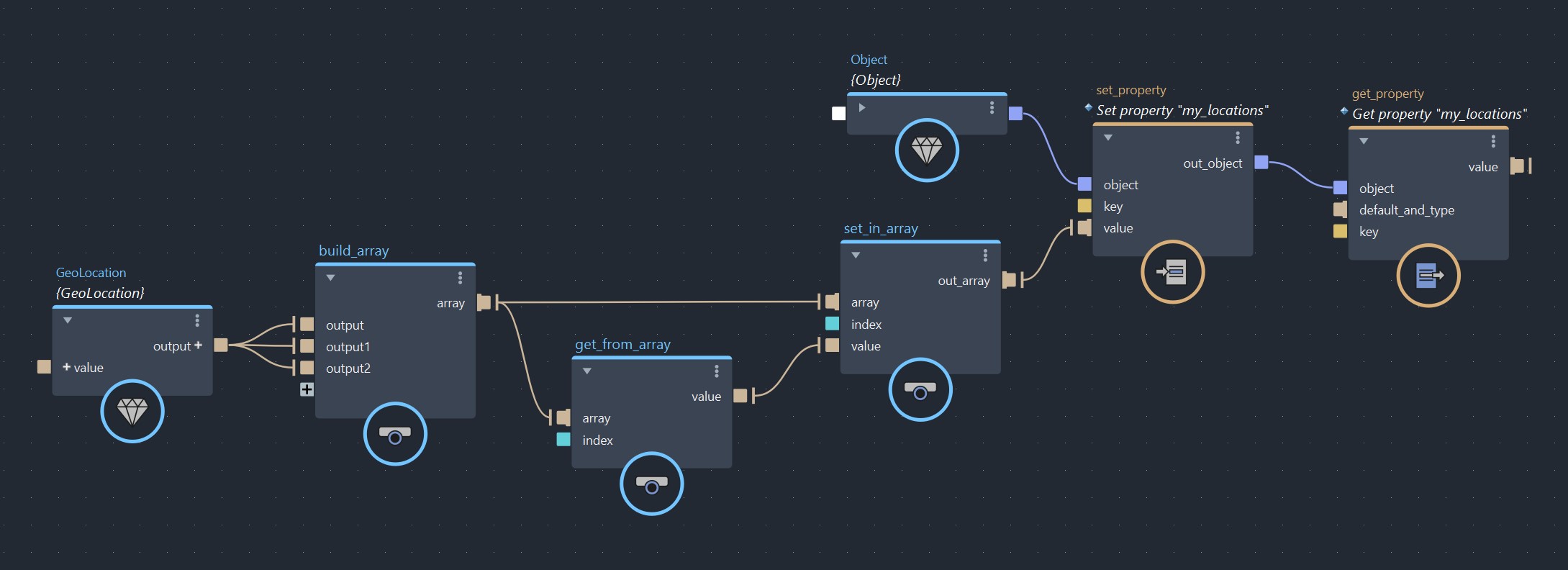
Another cool things about these data structures is that they works fine with Bifrost’s built-in array manipulation nodes like build_array, get_from_array, set_in_array nodes. You can also store them on objects using set_property nodes, and query them later on using get_property nodes.
Part 3: Custom data structures
Time to learn how to make our own custom data structure! But before this, there are a few things I’d like to talk about, regarding when and why you should use them, and also how to make the most out of them. Let me start by showing you one of my custom data structure I’ve used inside the ivy generator I’ve shipped in MJCG compounds 2.0.
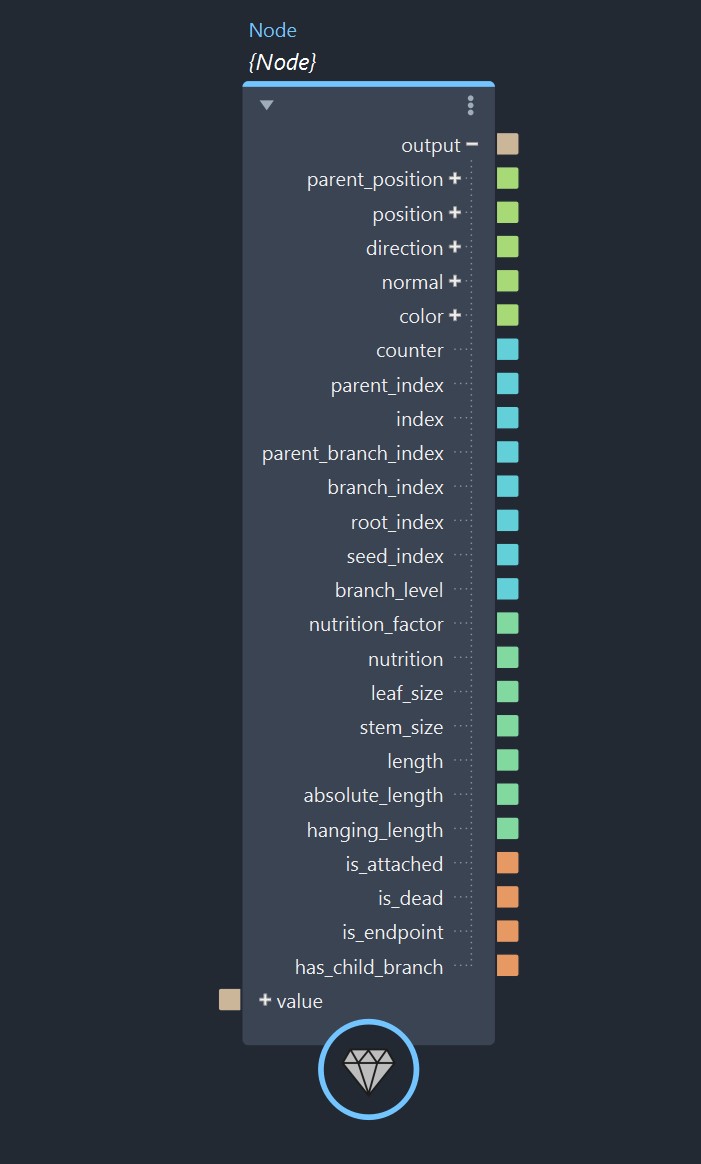
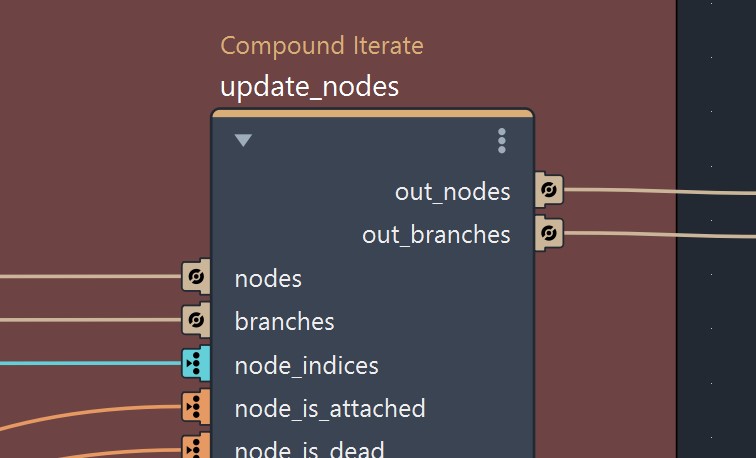
As you can see, there are quite a lot of members. Inside the ivy solver, at each growth step, all these members are getting updated several time in several different loops. This is needed in order to grow the ivy and to generate the strands and leaf instances geometries.
Can you imagine what the compound would look like if each loops had a port for every single members? and also all the wires? It would become a mess so big that it would just become unmanageable in a visual programming context.
Here instead, on this iterate compound, I only have to use one state port per data structure, which makes the compound clean and more efficient, as increasing the number of state / iteration ports results is very slight performance loss.
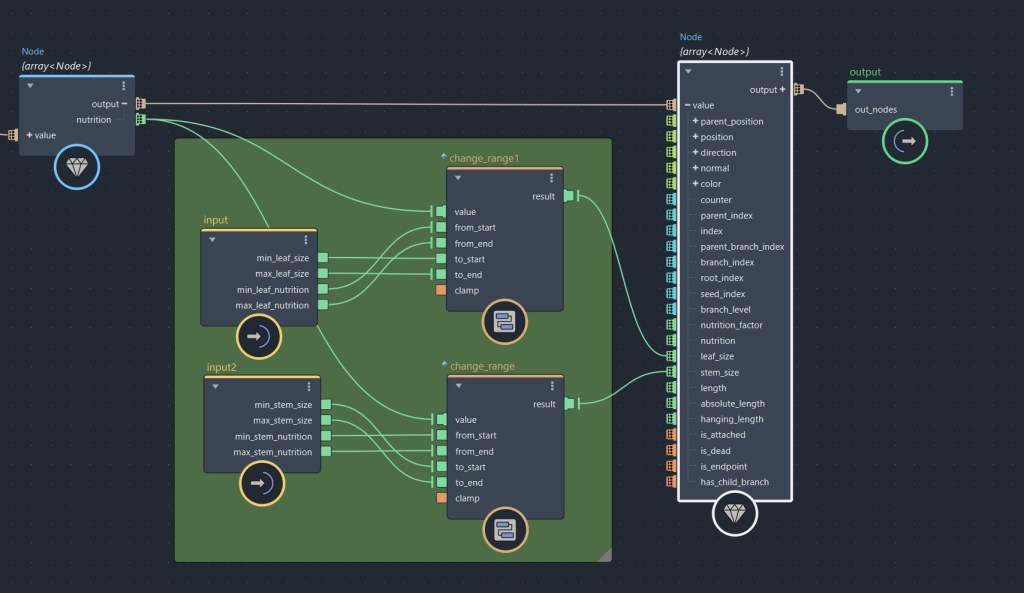
While you could do the same thing by storing each sub-data into an Amino object as properties, and feeding each objects into an array, there is another great feature I love about dealing with data structures which make them more convenient to use in advanced cases like this. In the following image, I show how you can use a data structure to update only one or a few members while preserving all of the others.
If you look carefully, you can see that there is a connection between output and value of the two value nodes. It is important to preserve this connection as this will allow us to preserve all the data structure’s members. Then, you can see that only the leaf_size and stem_size are plugged into the 2nd value node. By using the structure like this, we don’t have to connect every single members between the two value nodes. Only the members that have input connections get overwritten, while all other members of the structure remains untouched.
If we were to do the same using Amino object, we could certainly preserve each sub-data inside the object, but we would have to use a get_property node to extract each sub-data we wish to use, and then, in order to re-save these data on our object, we would have to daisy-chain some set_property nodes for each updated sub-data. This would results in using more nodes and therefore make the graph messier. Thanks to the data structures, we don’t need to deal with any of this. We just plug the updated data to the data structure’s members and voilà. No mess, no performance loss.
Enough talk! Time to create our own! To begin with create a JSON file, give it a proper name, and place it in our custom compound library. Because your compound will keep a reference to this file’s name, it is important to set it correctly at the beginning and not touch it again. In case you change its name, your compounds using this data structure should still load fine, but it may generates trivial error messages when Bifrost is loading, so keep that in mind.

And now the most important, the content of our custom data structure’s .json file. As you can see, the structure looks quite similar to the JSON file we’ve created in our custom enum tutorial. The difference is that here, we declare a data structure rather than an enum. There are two important things here so make sure to read the following carefully.
{
"header": {
"metadata": [
{
"metaName": "adskFileFormatVersion",
"metaValue": "100L"
}
]
},
"namespaces": [],
"types": [
{
"structName": "MJCG::MyDataStructure",
"structMembers": [
{
"memberName": "my_float3",
"memberType": "Math::float3"
},
{
"memberName": "my_uint",
"memberType": "uint"
},
{
"memberName": "my_bool",
"memberType": "bool"
},
{
"memberName": "my_float_array",
"memberType": "array<float>"
}
]
}
]
}
At line 13 is where we set our custom data structure’s namespace. Make sure to set it up correctly at first. If you start using the data structure in your compounds, and later decide to change it, all of the compounds using it will not load! And it may also prevent Bifrost to load correctly! So be careful about it. If you decide to change it later, you will have to edit all your compound’s JSON files with your favorite text editor, and replace all the namespace occurrences manually.
{
"structName": "MJCG::MyDataStructure",
"structMembers": [
{
Then, at line 16 & 17 is where we declare our data structure member’s name and data type. Here you should be careful about setting the data type correctly, or else, when loading Bifrost, invalid members will not be part of the data structure. Members are safer to modify than the namespace though. If you decide to change the member’s name or its data type later on, your compound will still load fine, the other members will still work as expected, but the ports connected to the modified members will get disconnected, so you’ll only have to reconnect a few ports. No big deal. A cool thing is that you can add members later as this will not impact anything that is using the structure. New members get append inside the member’s list and everything still works fine.
{
"memberName": "my_float3",
"memberType": "Math::float3"
},
Once our JSON file is ready, let’s reload Bifrost, get a value node, and let’s find our custom data structure in the Other tab of the Set Value Type dialog. Select the type, click OK, and voilà!
We have successfully loaded our custom data structure inside Bifrost. From now on it can be used anywhere from value nodes, array manipulation nodes, get / set property nodes, and all types of ports, from standard to iteration target ports, state ports and feedback ports. And thanks to Bifrost’s data type mechanisms, your custom data structure will be ready to be used as array without the need to do any additional work.

Part 4: Limitations
While custom data structures are quite flexible, there are a few limitations you should know about. First, if you want to cache objects that are holding custom data structures as properties, currently, these properties will not serialize into .bob files, so if your workflow relies on it you should avoid using custom data structures. (Thanks to Jonah Friedman for the feedback).
Another limitations is that you will not be able to store custom data structures on objects as geo properties. This is because the set_geo_property node is meant to be used with a restricted list of official data types, and therefore it does not support custom data structures. You can still store them on objects using standard properties though.

Finally, Bifrost will not allow you to expose these data types on the graph’s top level input / output port. This is because these data types doesn’t correspond to anything in the DCC. You can still transfer these advanced data structures between different graphs though. You just have to store them inside Amino objects using set_property nodes, and get them in the second graph using get_property nodes.
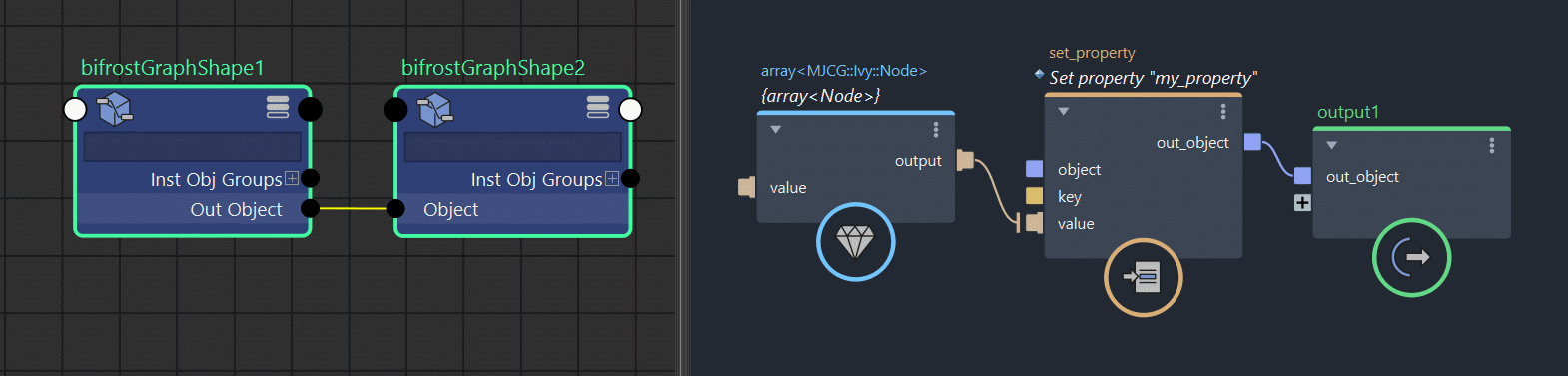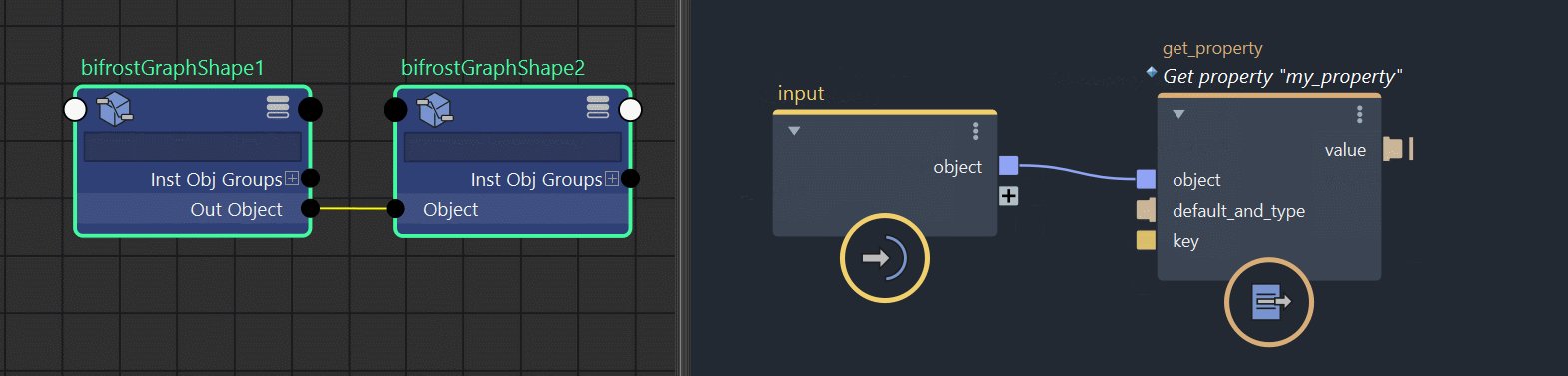
Part 5: Conclusion
So this concludes our tutorial on how to set up a custom data structure in Bifrost. If you are a beginner or not very familiar with visual programming in Bifrost, I would recommend to stay away from them, as custom data structures are meant to be used in advanced and complex scenarios. Most of the time, you are better just using standard Amino objects and store your datas as properties or geo properties. However, if you feel like you are at an intermediate or advanced level, then I definitely recommend making use of them when you are programming something more complex! Custom data structures can make visual programming more pleasant by decreasing the number of ports and wires needed inside your compounds, and they can also be handy when you want to update only one of a few of their members in an easy way.
I would like to conclude by announcing that a new Slack channel called Bifrost Addicts was born a few months ago, and it is a great place to ask for help and to share your Bifrost experiments. Most of you might have already joined, but if you have not feel free to join us, we are already 300 members there! You can join the channel HERE.
This is all for me. See you in another post!
